Anonymisation des données : pourquoi ? Comment ?
Nous parlions récemment de l’anonymisation des données dans notre précédent article de blog. La collecte des données doit respecter, entre autres, le principe de l’anonymisation, préconisée par le Règlement général sur la protection des données (RGPD).
L’anonymisation des données personnelles vise à rendre impossible et de manière irréversible, l’identification d’une personne physique à travers une donnée le concernant (nom, adresse e-mail, adresse postale, etc.).
In fine, il s’agit de protéger la vie privée de l’internaute et d’empêcher toute discrimination potentielle.
Un exemple concret d’anonymisation des données
Le respect des données personnelles et de la vie privée fait partie des préoccupations quotidiennes de nos clients (et donc des nôtres) !
L’exemple suivant concerne une mutuelle, constituée de plusieurs dizaines de milliers d’adhérents.
L’anonymisation des données personnelles d’un adhérent qui a a quitté la mutuelle doit se faire automatiquement au bout de 36 mois (si l’adhérent n’a pas demandé la suppression de ses données personnelles avant).

La logique d’anonymisation suit le schéma suivant :
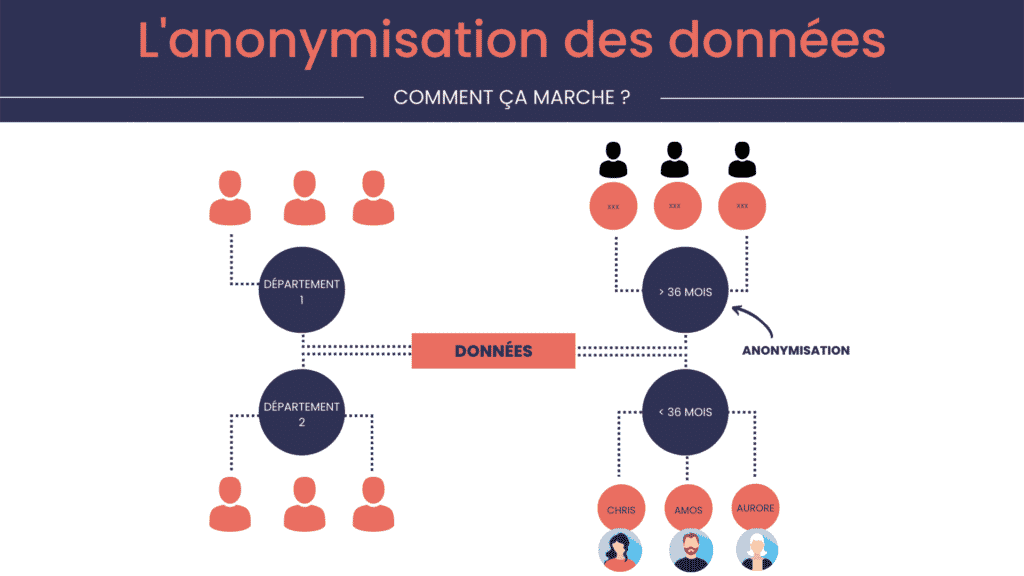
Comme on peut le voir, les différents départements de l’entreprise (commercial, administratif, comptable, etc.) ont accès aux données personnelles des adhérents pour la gestion quotidienne de leur dossier.
Celles-ci doivent donc être anonymisées au bout de 36 mois à partir du moment où l’adhérent a quitté la Mutuelle.
Comment procède-t-on à l’anonymisation ?
Très schématiquement, la procédure comporte deux étapes :
1. Répertorier toutes les données personnelles qui permettent d’identifier une personne physique (nom, prénom, adresse, e-mail…) et qui n’ont pas de valeur dans la perspective d’une réutilisation future.
2. Dans notre exemple, la deuxième étape consiste à remplacer la donnée par des chaînes de caractères non reconnaissables (XXXX) pour garantir l’anonymat de la personne physique.
Parlons (un peu) technique
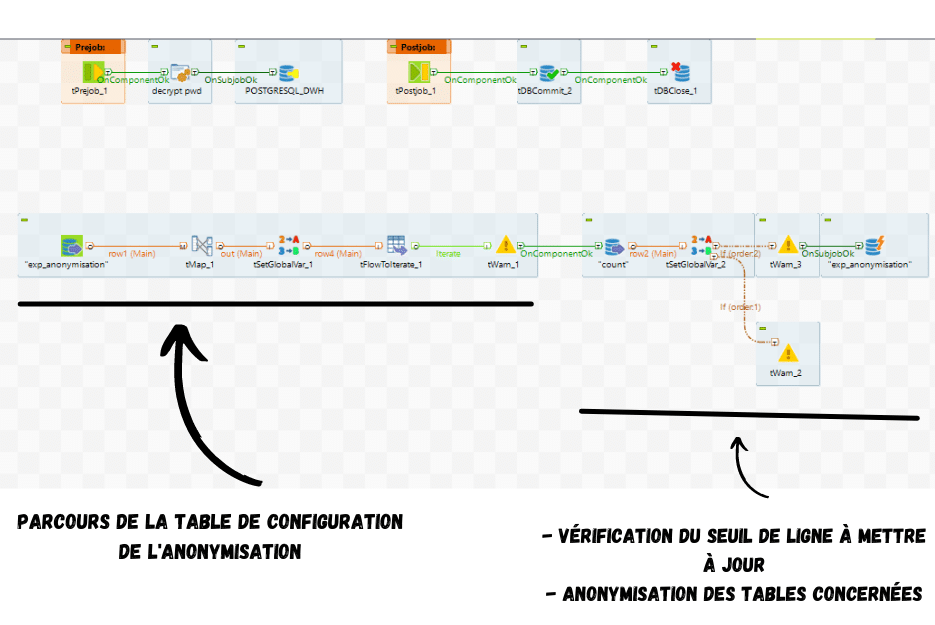
Ce remplacement se fait quotidiennement et de manière automatisée via Talend, un logiciel spécialisé dans l’extraction de données et dont Effidic est un utilisateur expert.
L’illustration suivante montre les deux grandes étapes à effectuer sur ce logiciel pour mener à bien l’opération :
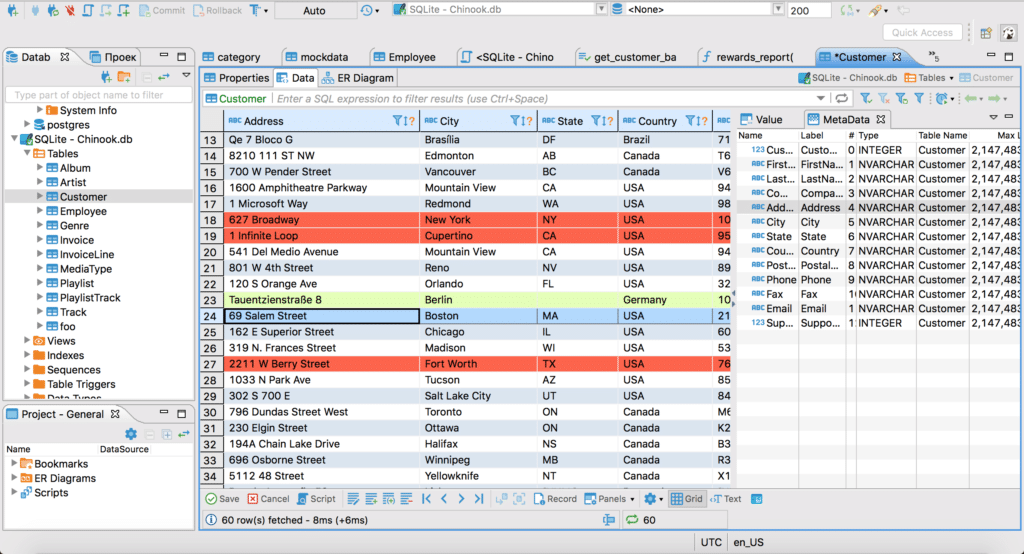
L’autre outil utilisé pour cette procédure est le logiciel DBeaver, qui permet de travailler sur les BDD mais aussi générer et tester des requêtes.
Les captures d’écran suivantes donnent un aperçu de l’interface de travail :
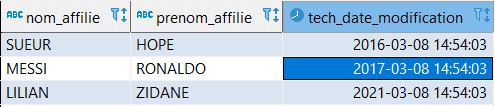
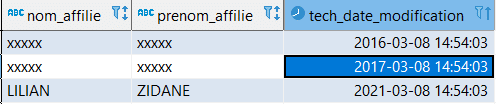
L’établissement d’un seuil maximal de requêtes sur cette table permet de bien circonscrire le périmètre de l’anonymisation. Autrement dit, si nous fixons ce seuil à 1000 lignes, l’anonymisation ne dépassera pas ce chiffre.
