Azure DevOps : la plateforme de gestion « serverless »
Azure DevOps, c’est quoi ?
Azure DevOps est un outil en mode SAAS édité par Microsoft et qui a pour objectif la gestion de projets. Il inclut tout particulièrement un dépôt GIT et outil de pipeline avec une approche « CI/CD » (distribution et intégration continues), autrement dit il permet l’automatisation des tests et des déploiements.
Ce processus consiste donc à introduire l’automatisation et la surveillance continues dans le processus de développement des applications et à faciliter un mode de travail collaboratif entre développeurs et opérationnels.
Les + d’Azure DevOps
- Sa plus grande force est d’être « serverless » : Azure DevOps est une solution en cloud et ne demande donc pas de serveurs dédiés et installés sur site (on premise). Il y a donc moins de contraintes de coûts, de licences ou de maintenance…
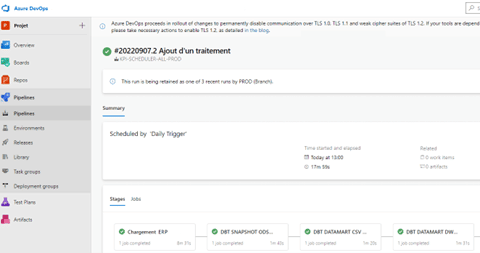
- Azure DevOps est une plateforme qui regroupe plusieurs outils et permet une gestion des tâches à travers un processus modélisé et une livraison entre les différentes strates/étapes de travail sur le projet.
En somme, un outil issu des nouvelles technologies cloud et qui fait le quotidien de nos équipes pour réaliser des projets agiles et collaboratifs.
La virtualisation via Docker
Le principe du « serverless » d’Azure DevOps repose sur l’utilisation de machines (ou images) virtuelles lors des traitements. Ces machines sont mises à disposition sur la plateforme Docker, qui permet de lancer les applications utiles au projet de traitement. Dans notre pratique quotidienne, nous utilisons des machines virtuelles équipées d’une version mise à jour Data Build Tool.
La virtualisation permet ainsi d’éviter toutes les contraintes de l’installation physique d’un serveur et des logiciels associés. Nous ne déployons que les outils dont nous avons vraiment besoin.
Autre avantage : à la fin des traitements, le serveur et les machines virtuelles mis à disposition par Azure DevOps sont supprimés évitant ainsi les manipulations de maintenance.
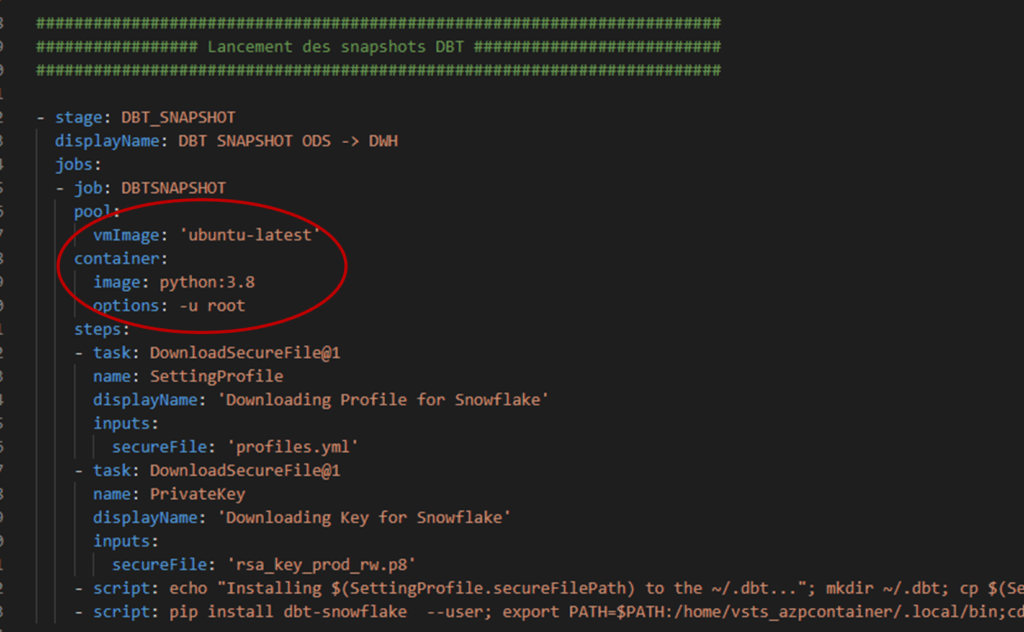
Les pipelines de données
Lors des processus de traitement sur Azure DevOps, la mise en place d’un Pipeline data se déroule en 6 étapes :
- Récupération des données sources via Talend
- Historisation des données via les snapshots DBT
- Chargement des fichiers de paramétrage via les « seeds » DBT
- Chargement des Datamarts via les modèles DBT
- Passage des tests d’intégrité via les tests DBT
- Rafraichissement des données Dataviz